It is relatively straightforward to establish the power and potential of human organs. The results are deterministic and not much different than animals. For example, my arm or leg can move only within a certain range and perform a limited number of known tasks.
On the other hand, the possibilities with the mind are unlimited. For example, it can plan and execute a drilling mission to dig tunnels in the moons Titan and Europa, all the while sitting here on planet earth! We can say that the mind is the most mysterious organ not only in the human body but in the entire universe.

There are some similarities between the functioning of the mind and Digital Signal Processing (DSP) techniques that we will explore today.
Background
Many scientists and philosophers have tried to decode hidden workings of the mind over the past millennia. There are at least two phenomena that have made this investigation difficult.
Enclosed Casing
Being soft and fragile, the brain is enclosed in a hard casing: the skull. At the time of this writing, it is not possible to observe the brain open and unpacked during its live performance. Instead, electronic and magnetic instruments are used to study the signals generated during the presence and absence of certain activities in different regions. Some of these tools are recording electrical activity in the brain (EEG) and creating images of the activity in each brain area (neuroimaging). According to David Eagleman, this is like trying to understand the nature and rules of a baseball game while holding a microphone outside the stadium:
"Sealed within the dark silent chamber of your skull, your brain has never directly experienced the external world and it never will. It’s like a prisoner trying to get information about outside through senses …"

While being enclosed does not hinder the study of other organs (e.g., heart or kidneys), analyzing the complexity of the brain is a different scenario.
Reference Framework
The output ideas of a mind are a function of both the input information and the previously stored information. We build new concepts largely on the basis of incoming information and on what we already know. As the saying goes:
We don’t see things as they are; we see them as we are.
Therefore, understanding the functionality of the brain has also changed throughout the scientific history. For example, it has been compared to clockwork and a hydraulic machine during the mechanical revolution, then to a telephone during the electrical age and now to a computer in the current world of computing and information technology. This is due to our own limitation of making deductions deeply rooted in our reference framework.

While it is more probable that an architecture far beyond our current knowledge is required to understand its workings, some of its functions certainly resemble the operations used in the field of DSP.
Encoding the Information
In many DSP systems as well as the brain functions, it is not the absolute values but the difference that matters. The perception is relative, not absolute.
Pulse Code Modulation (PCM)
One of the most widely used techniques to convert an analog signal into a digital format is Pulse Code Modulation (PCM). The amplitude of an analog signal can take on an infinite number of values over a continuous range. On the other hand, the amplitude of a digital signal is limited only to a discrete set of values.
We have also seen before that sampling on time axis and quantizing on amplitude axis are the two tools that are employed for analog to digital (A/D) conversion. This is done by rounding off the samples to the closest quantized level at regular intervals as drawn in the figure below. These quantized levels are assigned binary representations according to the number of bits available for this conversion. The figure below illustrates 4 bits and $2^4=16$ corresponding levels, although practical ADCs work with thousands of such levels. This implies that one sample is usually represented by at least 14 or 16 bits for precision.

In this simple example, the generated bit sequence is given as follows.
\[
1000 ~~~ 0100~~~ 0001~~~0001~~~0010~~~0101~~~1001~~~1101~~~1111~~~1111~~~1101~~~~1001
\]
Quantization Noise
Notice above the difference between the actual value and the quantized sample at a preset level. This gives rise to quantization noise.
This quantization noise can be reduced by any of the following techniques.
- Increasing the number of levels that is expensive in terms of memory and power.
- Reducing the peak signal amplitude that makes the same number of levels fit within a smaller voltage difference.
The second option above is more straightforward to implement.
Now if our purpose is not to reduce the quantization noise but to save memory and processing power, we can still reduce the peak amplitude and now utilize lesser number of bits for this purpose. For example, if the peak amplitude is brought down to a quarter, then this results in a saving of two bits. Later, we will see that this energy efficiency parallels how mind processes the information.
Differential Pulse Code Modulation (DPCM)
The peak signal amplitude can be reduced by observing that the next value of a sample can be guessed to a reasonable extent if the previous value is known. This means that instead of encoding the sample values, we can simply encode the difference between the successive sample values.
If the new signal sample is denoted by $s[k]$, then we have
\[
e[k] = s[k]-s[k-1]
\]
At the destination, the new sample can be reconstructed by
\[
s[k] = s[k-1]+e[k]
\]
Why is this scheme more helpful? Because if the sampling theorem is satisfied, the difference between successive samples is much smaller than the original sample values. In other words, the peak amplitude of $e[k]$ is lesser than that of $s[k]$. This produces fewer number of bits per sample.

In an actual DPCM implementation, we predict the $k$-th sample value of $s[k]$ from a knowledge of previous samples at the transmitter. But that is discussed later in the context of prediction.
In summary, $e[k]$ is a signal with a small peak amplitude that can be represented with a significantly lesser number of bits as compared to the original sample values.
Delta Modulation (DM)
For a reasonably oversampled signal, the correlation between successive samples is high and the signal can be encoded by using only two levels, i.e., either the next sample is higher or lower than the previous sample, a logic that requires only 1 bit of information. This is essentially a 1-bit DPCM, commonly known as Delta Modulation (DM). With a slight modification outside the scope of this article, an integrator is included in the process and the converter is known as Sigma-Delta ($\Sigma-\Delta$) Modulation. Many of the ADCs today are based on this inexpensive technology.
There are many other DSP applications in wireless, audio and video and even electronics that rely on a similar idea of using difference signals. But that will make the article more technical than necessary. The above example serves our purpose well.
The Perception of Mind
In the past few centuries, we see the purpose of life as achieving great feats in our career, or utilizing our full potential. This is due to ecosystems of food and security built within the human societies. For all the remaining part of history, life has mostly been about survival. And having energy was the basic condition of surviving in any environment.
Now a human mind consumes about 20-25% of our rest time energy. Consequently, it tries to operate in as efficient a manner as possible. This efficiency is reflected in how the mind perceives and navigates the world around us by processing only the minimum amount of information. Surprisingly, this phenomenon is quite similar to the difference and prediction framework described above for encoding information.
Memory
In his book Thinking Fast and Slow, the psychologist Daniel Kahneman describes the two selves we all have:
- the experiencing self that actually operates in the moment, and
- the remembering self that recalls the memory of that experience.
From a study of a medical procedure on patients, he found that patients did not report the total amount of suffered pain but only what they remembered.
\[
\text{Total remembered pain} \neq \text{Total experienced pain}
\]
Their findings about the remembering self were as follows.
- Peak-end rule: The global retrospective rating was well predicted by the average of the level of pain reported at the worst moment of the experience and at its end.
\[
\text{Total remembered pain} = \frac{\text{Worst or peak pain}+\text{End pain}}{2}
\]

- Duration neglect: The duration of the procedure had no effect whatsoever on the ratings of total pain. A consistent amount of pain for a longer duration of time is not perceived as painful as it actually was.

What do you think is the underlying factor in the above conclusions?
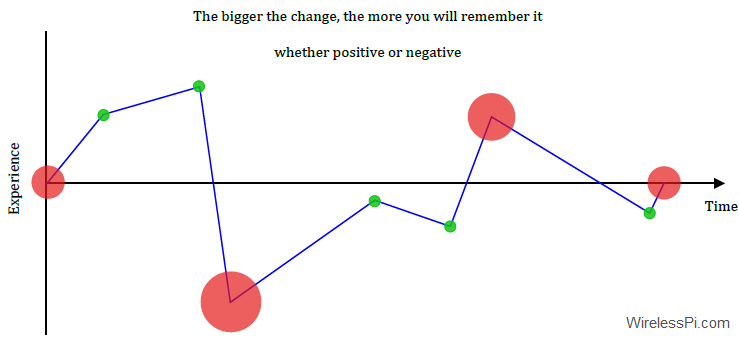
Clearly, the encoded sample just depends on the difference between successive samples, instead of the absolute sample values themselves. What gets etched in the mind are the moments of maximum deviation.
I am confident that the researchers observed the peak-end response because they were looking for the peak-end response. In reality, these points represent the maximum deviation whether it is a peak, or more than one peak, or some other significant change during the event.
- Even the start of a procedure, for example, is giving rise to something from nothing. Recall that every single tip you received for an important presentation included how to start it on a strong note, or that the first impression is the last impression.
- On a similar note, the end of a procedure is going back to nothing from something. This is why they say: All is well that ends well.
Therefore, I suggest modifying the peak-end rule as start-peaks-end rule. An even better terminology is significant deviations.
In words of Jim Kwik,
Every second, your senses gather up to 11 million bits of information from the world around you. Obviously, if you tried to interpret and decipher all of them at once, you’d be immediately overwhelmed. That’s why the brain is primarily a deletion device; it’s designed to keep information out. The conscious mind typically processes only 50 bits per second.
What makes it through the filter is determined by the part of the brain called the reticular activating system, or RAS for short. The RAS is responsible for a number of functions, including sleep and behavior modification. It also acts as the gatekeeper of information through a process called habituation, which allows the brain to ignore meaningless and repetitive stimuli (emphasis mine) and remain sensitive to other inputs.
In conclusion, to register anything in the brain, it is the difference that matters, not the absolute values! That is why a surprise or an unexpected part is necessary in making someone remember your point during a presentation or a conversation.
History
At the next level above an individual memory, history is our collective memory of events. Given the hundreds of thousands of years worth of data, or at least 10,000 years since the dawn of agriculture, what do you think fills up the history books? Only the large deviations from a normal life. This is why you read about wars, treaties, plagues, religions and inventions but rarely about the peace or the daily routine of people living in a kingdom.
Media
This same phenomenon also guides the selection criteria adopted by the news channels. Only the most sensational makes it to the audience. The news you watch are about shark attacks or other extraordinary events but the probability of dying from these causes is miniscule as compared to plain heart disease or diabetes. Why? Because the sensational generates a larger deviation than the mundane, attracting more eyeballs that leads to audience growth and high advertisement revenue.

And the social media are not very different. A family having a calm and relaxing time together (e.g., during a reading session) will not go viral. Only the event that lies beyond 99.99% of what we have already seen. The more it breaks our expectations, the more views it gets.
Life Satisfaction
This is too vast a topic to touch upon in a short article but I will mention how life satisfaction and happiness also exhibit the same relative scale as in digital conversion.
Taking a long view of history, the ancient hunter-gatherers were largely an egalitarian society. When you have to move from place to place after some time, collecting possessions is not useful and without possessions, there is little to form hierarchies among the people. Agricultural revolution brought huge benefits for some (e.g., kings, priests, knights) but misery for most of the remaining population.
And then there were wars and plagues. While sleeping at night, you were not sure if you would wake up free or under attack by the neighbouring tribe or kingdom. Simple injuries like a cut on the skin took powerful kings to the grave. That is why in the Gaussian curve of the figure below, I have shown the quality of life of ancient kings as a little worse than those living in modern free societies. At least a huge majority of the world population today benefits from an array of treatments unavailable just a few decades ago. Not to mention the water coming in the taps on demand (no 5 km walks with the buckets), electricity, 24/7 availability of food and the likes.

Looking from this angle, most people should be quite satisfied with their lives today. But research studies show that this is not true. Why?
- Humans are remarkable at adaptability. This is the trait that helped them spread from Africa to different climates and conditions in other continents. However, this also means that we also adjust our ‘normalcy meters’ according to the situation. So if you spend two weeks in a paradise island, that will soon look like a new normal. This is similar to taste. To truly enjoy the dessert, we need to eat our broccoli and spinach first. Like signal encoding, it is the difference that matters.
- We only absorb and process the information coming around us. And in our own small bubble of history, we have another Gaussian curve ranging from poor to middle class to the rich. We look at the positive extreme because this is what is channeled to us by the media (as we saw above) or the best aspects of the lives of people like us from their social media. We are consistently bombarded with the best of the best that should generate a large deviation from the mean and catch our attentions (the difference signal).
On the other hand, we do not watch scenes of death and destruction of the negative extreme. To sum up, only the positive maximum deviation makes way to our minds.
- What we see sets our expectations. The expectations of what we should be highlights what we are not. Since happiness is based on emotions that come and go, I would use the term life satisfaction that can be written as follows.
\[
\text{Life satisfaction} = \text{Reality} -\text{Expectations}
\]Thus, our high expectations on the right hand side drown even the great reality we live in today.
Towards Predictions
We mentioned above that Differential Pulse Code Modulation (DPCM) actually does not take into account the difference signal between successive values but the difference signal between the actual values and their predictions. In the ideal case of perfect prediction, $e[k]$ is zero and there is nothing to encode! In the real world, $e[k]$ is a signal with a very small peak amplitude that can be represented with a significantly lesser number of bits as compared to not only the original sample values but also the sample differences!
We predict the $k$-th sample value of $s[k]$ from a knowledge of previous samples at the encoder. Let us call this prediction $\hat s[k]$.
\[
e[k] = \hat s[k] – s[k]
\]
Now we can encode only the prediction error $e[k]$ which should be smaller than even the sample difference. The predictor algorithm for this purpose can be quite complex. In delta modulation, the signal is sufficiently oversampled and the prediction is simply the previous sample. Prediction algorithms are extensively used in efficient audio and video systems.
This is how the human mind works too! Jeff Hawkins provides a memory-prediction framework of the mind in his book On Intelligence. Here is an excerpt below.
Our brains use stored memories to constantly make predictions about everything we see, feel, and hear. When I look around the room, my brain is using memories to form predictions about what it expects to experience before I experience it. The vast majority of predictions occur outside of awareness.
It’s as if different parts of my brain were saying, “Is the computer in the middle of the desk? Yes. Is it black? Yes. Is the lamp in the right-hand corner of the desk? Yes. Is the dictionary where I left it? Yes. Is the window rectangular and the walls vertical? Yes. Is sunlight coming from the correct direction for the time of day? Yes.” But when some visual pattern comes in that I had not memorized in that context, a prediction is violated. And my attention is drawn to the error.
Of course, the brain doesn’t talk to itself while making predictions, and it doesn’t make predictions in a serial fashion. It also doesn’t just make predictions about distinct objects like coffee cups. Your brain constantly makes predictions about the very fabric of the world we live in, and it does so in a parallel fashion. It will just as readily detect an odd texture, a misshapen nose, or an unusual motion. It isn’t immediately apparent how pervasive these mostly unconscious predictions are, which is perhaps why we missed their importance for so long. They happen so automatically, so easily, we fail to fathom what is happening inside our skulls. I hope to impress on you the power of this idea. Prediction is so pervasive that what we "perceive" — that is, how the world appears to us— does not come solely from our senses. What we perceive is a combination of what we sense and of our brains’ memory-derived predictions.
… Prediction means that the neurons involved in sensing your door become active in advance of them actually receiving sensory input. When the sensory input does arrive, it is compared with what was expected.
Whether we are finishing others’ sentences in our heads or guessing the step location while climbing the stairs, our minds are unconsciously monitoring the environment and predicting what comes next according to our expected mental models (imagine spotting a tiger instead of a cat in your neighbor’s lawn). It is the key to intelligence, whether natural or artificial. And the performance of any future AI will depend on the strength of its predictions.