In a previous article, we had a little introduction to the big picture of machine learning. More than what is it is, we focused on what it is not. Today we explore the category of supervised learning that opens the door to our understanding of advanced machine learning techniques.
To see how supervised learning is proliferating in all walks of life, consider a few examples below.

- Insurance companies can predict the costs of storms damages for the future years due to climate change and adjust their premiums accordingly.
- During an interview, companies can classify the candidates with high and low emotional intelligence from their facial and verbal expressions.
- Investment companies can predict the real estate prices in different areas of the country to distribute their investments for higher returns.
We start with the introduction below.
Introduction
You might remember how you learned simple mathematical operations on integers in primary school that was quite easy.
\[
6+9 = 15
\]
Later, the letter $x$ was introduced in algebra lessons after a few years that looked like a stranger in a crowd of numbers. I really liked it.
\[
3x-12=15
\]
Clearly, the answer $x=9$ is found by moving other numbers around. Next, we became familiar with linear equations that map how another variable $y$ depends on the independent variable $x$.
\[
y = 2x+7
\]
It is straightforward to find a $y$ for any $x$. This can be generalized as follows.
- A number of inputs can be collected into a vector form, say, $X$.
- A number of outputs can be collected into a vector form, say, $Y$.
- The input-output relation can be any function $f(\cdot)$, not necessarily a linear one.
\[
Y = f(X)
\]
Again, $Y$ can be found for any $X$ through the function $f(\cdot)$. In the scenario under consideration, a set of linear equations can be used to solve interesting real world problems, see the following example.
John is 4 inches taller than Ann. The sum of their heights is 128 inches. What are their individual heights?
Solution: Treat their heights as two letters in algebraic equations.
\[
\begin{aligned}
J &= A + 4 \\
J + A &= 128
\end{aligned}
\]
For solution, plug the value of $J$ from the first equation into the second equation.
\[
A + 4 + A = 128
\]
Therefore,
\[
A = 62~\text{inches} \qquad \qquad J = 66~\text{inches}
\]
We can say that $Y$ can be easily found when $f(\cdot)$ and $X$ are known.

The next step takes us towards a simple understanding of supervised learning.
Supervised Learning
Operating in the real world, we have many input variables $X$’s and we also know many output variables $Y$’s. For this set of data, our challenge is to find the function $f(\cdot)$!

This function should be a reliable map of input to output so that we can utilize it for finding
- any new output $Y$, or
- categories of $Y$
by plugging in relevant new inputs $X$.

In words, we have labeled data with correct outputs already known and we want to find the underlying relation in terms of an algorithm. This is by no means a trivial task.
Each such solution has an associated cost in the form of an error term.
\[
Y = f(X) + e
\]
The target is to keep the error $e$ small, i.e., to make accurate predictions. In a way, this is not much different than an equalizer that learns the channel behavior during the training stage and compensates for those effects in the demodulation stage.
Supervised Learning Techniques
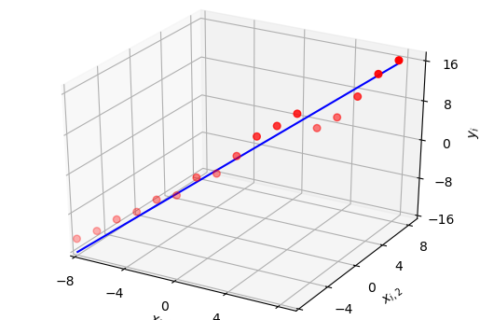
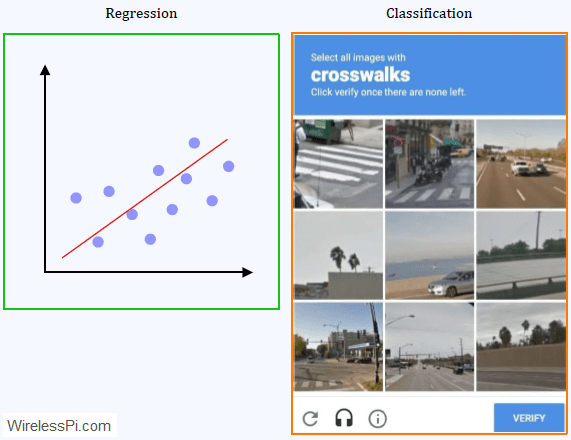
As hinted earlier, supervised learning can help us predict a continuous-valued output or organize into discrete categories, commonly known as regression and classification problems, respectively.
Regression
Given a continuous-valued input and output set, regression finds a relation between them such that new outputs can be predicted (on a continuous-scale) for given inputs. For example:
- Given the past record of storm damages, worsening global warming and vulnerability of a given location, insurance companies want to know how their costs are going to change year by year. Regression can help them estimate the proper premiums customers should pay in each area (a continuous-valued output).
- In wireless communication, channel estimation is another problem that can be solved through regression techniques.

An intuitive guide to linear regression is the topic of a later article.
Classification
In classification algorithms, the target is to categorize the inputs into discrete outputs. For instance:
- While Google CAPTCHA is forcing you to indicate 3 crosswalks in 9 photos, it is determining whether you are a human or a spam bot. This is a classic example of a dumb machine classifying the inputs into humans and bots. A few years down the road, we will have intelligent machines differentiating between humans and other intelligent machines (the point of true singularity?).
- In wireless communication, blind modulation classification is another example in which we have a set of received samples and we have to determine the modulation, symbol rate and other such parameters.
There are other algorithms one can employ for classification problems such as logistic regression and k-Nearest Neighbors (k-NN). Finally, you can read the article on Artificial Intelligence (AI) here.